2 months of my study will go here <TODO>
Chatbot For Aricent.com
Following retrieval based approach - http://www.wildml.com/2016/07/deep-learning-for-chatbots-2-retrieval-based-model-tensorflow/
1st step is data preprocessing to fit above model.
Data is in plain question and answer format like -
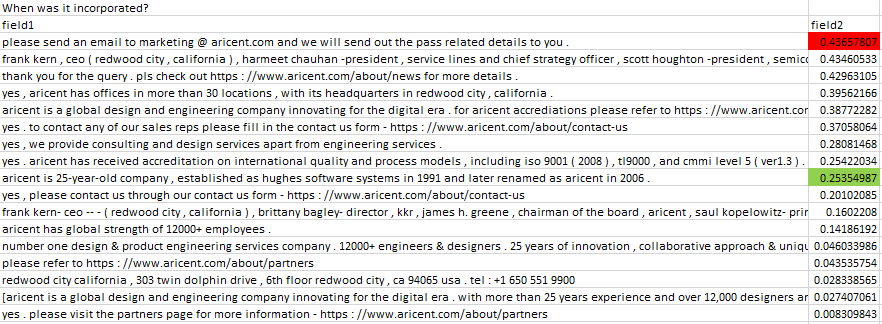
Question - When was Aricent established?
Answer - In 1992 Aricent was established.
The retrieval model expects three files
train.csv , valid.csv and test.csv.
Facing problem in training models, as sometimes the classification model classify wrong and retreival model end up ranking answers that are not correct if the set of answers are very close to each other.
To resolve these issues I started first by stemming and lemmatization of the dataset, also earlier dataset was pipe separated, i made it comma separated. Then i covered a sentence in double quote. Then i removed special characters like (, & and if there were two questions in one line itself, i separated them out. Having done this, i saw improvement in Classification model. But retreival model still eludes me.
After this i went back to the above retreival based post which also has link for ubuntu corpus dataset preparation, i cloned that. Now i format my data set as a dialog between two persons, each question and answer becomes a question by person_ask and a response from person_ans to person_ask as answer.
I create separate file for each one of the question. And now i use ubuntu corpous generate.sh script to generate train,valid and test data set. This script create dataset as expected by reterival based model originally. Now I trained my model till 22000 step. I tested this model by sending raw question and response ( i.e. without the steps performed by generate.sh script of ubuntu data set ), still a bad response. Then I changed the RateResponse script to lemmatize and stem the test questions and answers. To my surprise the performance improved to above 90%.
So, lemma and stem is important to generalize in the test dataset!!
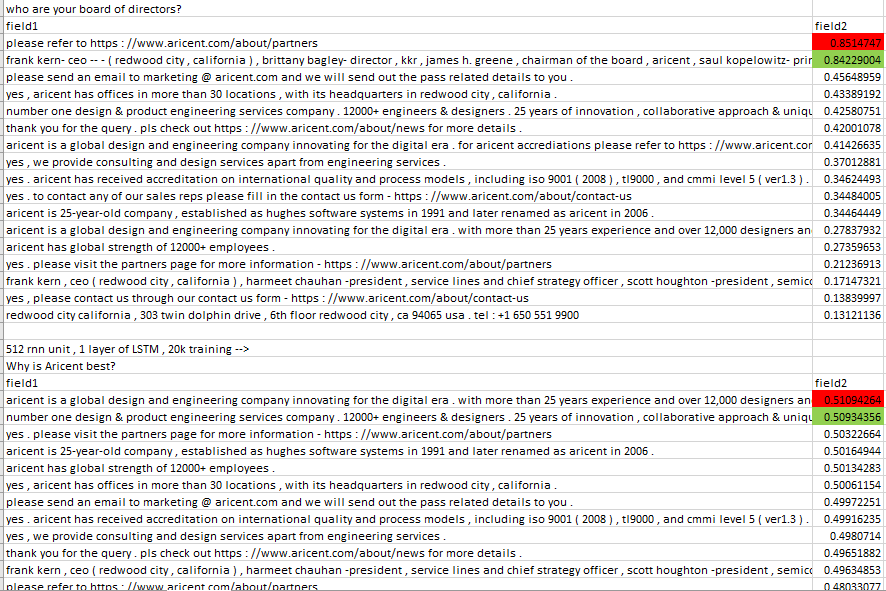
Now I saw that the exact question gets correct responses but using exact question is not correct approach ( when i change the questions or re phrase the question the performance of the model drops Not known by how much! )
I went deep into retreival model - it is a dual encoder meaning 1st the input sentence ( consider batch_size = 1 ) is converted to vectors using glove pre trained vectors, after that it is passed through LSTM cell of 256 units - this is 1st encoding and then this is multiplied with a weight matrix - this is 2nd encoding.
For using glove pre trained vectors i had to re create the training set without lemma or stemming because in the pre trained vector the words are not stemmed or lemma, i only tokenized the word. After this i used 300 dim and trained the model with 256 rnn unit and batchsize of 64, it trained till 49k steps - what i saw was that the response on the training set was not correct..it generalized too much!!?- dont know... ( max context and utternce length was very high at 460 )
Next i decreased the dim to 100 and kept all other hparams same and trained it again till 20k steps, I saw it got better on question from dataset but not much better!. Of course still it can't answer the re-phrased question with increased accuracy. ( I AM STILL NOT LEMMA AND STEMMING THE DATASET - I KNOW STEM AND LEMMA WILL INCREASE THE ACCURACY FROM ABOVE ) Pic: Dual encoder model from retreival based approach.
Pic: Dual encoder model from retreival based approach.
Next I kept the dim to 100 only and increased the rnn units to 512 and kept the learning rate constant at 0.001,
till here i was getting loss uptill 11%
One immediate change i saw in performance of training was time, it increased by 50%, linearly connected to rnn units.
Next after 9k steps I stopped and decreased the learning rate by half to 0.0005 and let it run till 17k step,
till here i was getting loss uptill 7%
Next after this, changed the learning rate again to 0.0001 and let it run till 22k steps,
the max loss increase to 11% max, but i saw that the network was able to hold loss at around 3%.
Next after this i further decreased the learning rate to 0.00001 and let it run till 26.5k steps.
the max loss increased to 12% but the network was able to hold avg loss at around 3-4%.
Time to check the response from the dataset!
<TODO>
<TODO>
vector(why)-vector(how)
vector(better)-vectory(good)
This is because when i use
why is aricent better? --> correct result
if i use
how is aricent better? --> correct result
if i use
why is aricent good? --> correct result
need to check the difference!
<TODO>: what does vector look like for unseen word while prediction, i know that it has id 0.
Okay after checking few examples, i see the accuracy has not improved much, although it is impressive on a unstemmed and unlemmatized data. I think the accuracy is around 90% max , it is failing completely with some of the TESTING questions.
Give the small size of the dataset we have, i was able to check to find the in correct response questions, but with bigger dataset this will not be possible. I feel that this model cannot work optimally unless the data is stemmed and lemmatized, thus using pre trained vocab is not feasible.
<TODO> : replace this model with sequence to sequence model and check same things.
Given the problem at hand i.e. to be able to understand different re-phrases of same question and answering correctly there is another design solution that comes to mind, what if there was a layer before retreival model, that maps rephrased questions to the original dataset questions - does this sound over engg ??
Then what could be this model ? what it will do in details?
This model basically can be of two type
- Classify a question to a given set of question - basically what our retreival model is doing with answers. This model is again a problem because if i have 100 questions in a class, i will have to first run question asked by the user with 100 of this questions and rate it. Phew! again this model will not rate it properly else it could have rated the answers correctly in first place only!
- Translate a question to one of the questions from given set.
adding one more LSTM after the LSTM in the above pic, what happens? how does network behave?
I added 3 layers of LSTM, had to change code to following,
def lstm_cell():
return tf.contrib.rnn.LSTMCell(
hparams.rnn_dim,
forget_bias=2.0,
use_peepholes=True,
state_is_tuple=True)
cell = tf.contrib.rnn.MultiRNNCell([lstm_cell() for _ in range(3)],state_is_tuple=True)
Had to change code statement from rnn_states to rnn_states[2] because it returned tuples of state,output from each LSTM cell.
<TODO>: is the gradient being backpropogated from last LSTM to last-1 LSTM?
Training time increased further and now time to complete 100 step takes 67seconds.
After 10k step i reduced the learning rate from 0.001 to 0.0001.
After 12k step i see that loss is ranging from 0.005 - 0.09..
After running few question, i saw that the performance of model has improved significantly over the model that was trained with 1 LSTM cell. From 4-5 questions that i checked on which previous model failed to respond correctly, i saw this model gave correct response and in most cases the score for correct response was much higher than incorrect response. This model seems more confident in correct answers.
Model trained with 1 LSTM layer ( 256 or 512 rnn units )
all failed to rank correct response higher. Also the scores were very close among all the answers.
 Model trained with 3 Layers of LSTM ( 256 rnn units ) till 13k steps only. Learning rate was dropped from 0.001 to 0.0001 after 9k steps.
Model trained with 3 Layers of LSTM ( 256 rnn units ) till 13k steps only. Learning rate was dropped from 0.001 to 0.0001 after 9k steps.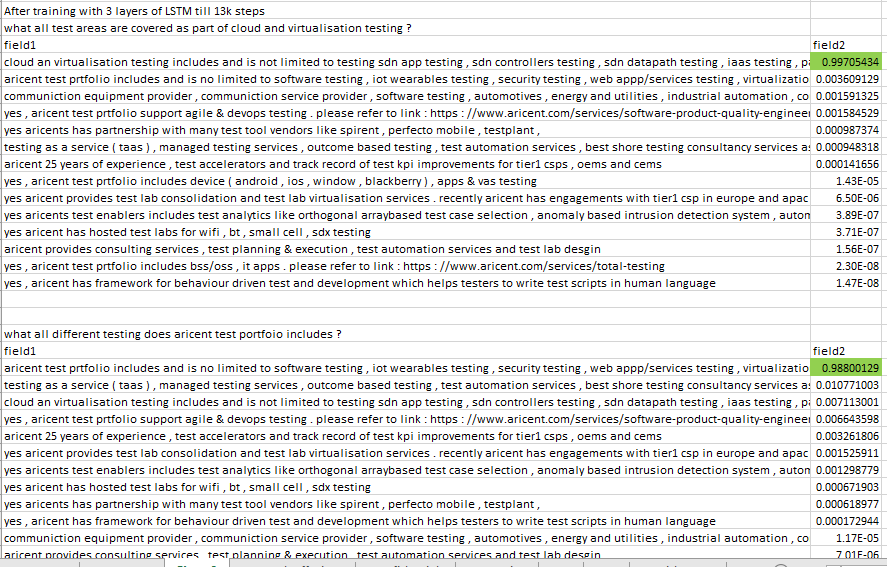


So it is clear that using miltilayer LSTM is correct approach.
Full code here - <TODO>: git hub link to include.
I changed the rnn unit to 128 and reduced the maxsentence lenght to 100 also changed the TEXTFEATURESIZE to 100 from udc_input.py, then when i tried to run the code, it failed with error,
InvalidArgumentError (see above for traceback): Name: <unknown>, Key: context, Index: 0. Number of int64 values != expected. Values size: 160 but output shape: [100]
[[Node: read_batch_features_train/ParseExample/ParseExample = ParseExample[Ndense=5, Nsparse=0, Tdense=[DT_INT64, DT_INT64, DT_INT64, DT_INT64, DT_INT64], dense_shapes=[[100], [1], [1], [100], [1]], sparse_types=[], _device="/job:localhost/replica:0/task:0/cpu:0"](read_batch_features_train:1, read_batch_features_train/ParseExample/ParseExample/names, read_batch_features_train/ParseExample/ParseExample/dense_keys_0, read_batch_features_train/ParseExample/ParseExample/dense_keys_1, read_batch_features_train/ParseExample/ParseExample/dense_keys_2, read_batch_features_train/ParseExample/ParseExample/dense_keys_3, read_batch_features_train/ParseExample/ParseExample/dense_keys_4, read_batch_features_train/ParseExample/Const, read_batch_features_train/ParseExample/Const_1, read_batch_features_train/ParseExample/Const_2, read_batch_features_train/ParseExample/Const_3, read_batch_features_train/ParseExample/Const_4)]]
Then, i changed back the TEXTFEATURESIZE in udc_input.py change to 160 and re-ran it, it is now running.
This is being done to check how reducing rnn units impacts the final outcome of the model. Learning rate stays at 0.001.
Results are :
Trained the model till 12.5k steps with droping learning rate from 0.001 to 0.0001.
While training highest error rate around 12k steps was 14%, error rate ranged from 0.006 to 0.14
The time taken to train the model reduced by half.
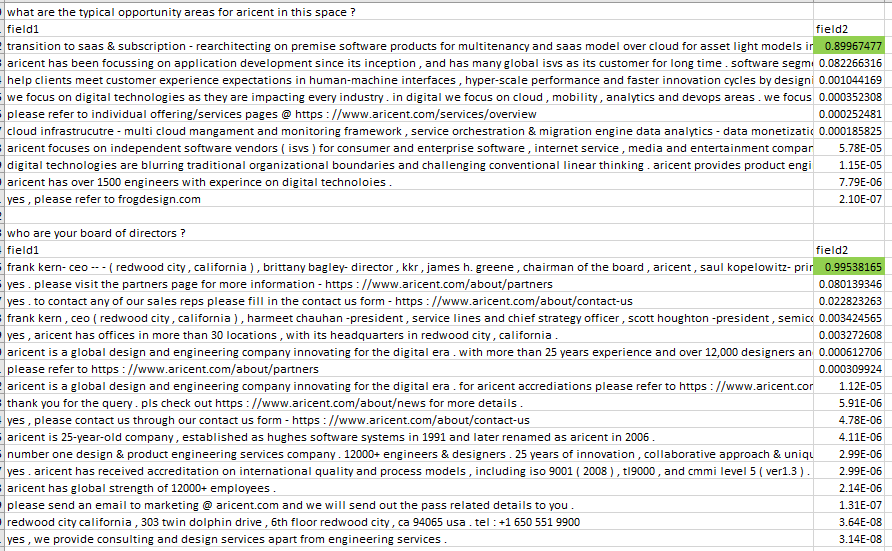
One big change that i saw in the prediction from this model was that it got more confident on the questions that it was not confident on while trained with 256 rnn 3 LSTM layers. ( Note: right now it is trained with 128 rnn units and 3 LSTM layers )

 For both questions previous model scored the correct responses as - 0.02740995, 0.015536938 respectively.
For both questions previous model scored the correct responses as - 0.02740995, 0.015536938 respectively.
However, this gives me doubt why does it improves when i reduced rnn units --- why rnn units is this way important ?
model gives correct predictions for the questions i checked.
Lets try Intent and Entity recognition from link - https://medium.com/rasa-blog/do-it-yourself-nlp-for-bot-developers-2e2da2817f3d
Here it is claimed that he can exceed the performance of cloud based apis in determining intent and entity using custom script.
Intent recognition,
code,
from mitie import *
import os
files = os.listdir('/home/cdpai/tensorflow-models/ticket_classification/data_backup_3')
data = {}
for fn in files:
fh = open(os.path.join('/home/cdpai/tensorflow-models/ticket_classification/data_backup_3',fn))
lines=fh.readlines()
fh.close()
data[fn]=[]
for ln in lines:
tokens=tokenize(ln)
data[fn].append(tokens)
trainer = text_categorizer_trainer("/home/cdpai/tensorflow-models/MITIE/MITIE-models/english/total_word_feature_extractor.dat")
for dat in data.keys():
for arr in data[dat]:
trainer.add_labeled_text(arr,dat)
trainer.num_threads = 4
cat = trainer.train()
cat.save_to_disk("new_text_categorizer_pure_model.dat",pure_model=True)
cat2 = text_categorizer("new_text_categorizer_pure_model.dat",'/home/cdpai/tensorflow-models/MITIE/MITIE-models/english/total_word_feature_extractor.dat')
question='What does Aricent do?'
pred, conf = cat2(tokenize(question))
print ("predict Intent of question '{0}' to be {1} with confidence {2}".format(question,pred,conf))
It took some time to train, not much though. It uses SVM internally.
It compared with deployed CNN ( no glove, stem dataset ) in following manner, MITIE library that i used - i didnt optimize it however, it held its ground good enough. CNN was kind-of optimized to some extent, still it got its ass kicked.
MITIE library that i used - i didnt optimize it however, it held its ground good enough. CNN was kind-of optimized to some extent, still it got its ass kicked.
I added the part in eval.py to extract scores from the prediction made, code is,
print('Start Predictions')
predictions = graph.get_operation_by_name("output/predictions").outputs[0]
print(predictions)
scores = graph.get_operation_by_name("output/scores").outputs[0] #Added
print(scores) #Added
# Generate batches for one epoch
print("Start batches")
batches = data_helpers.batch_iter(list(x_test), FLAGS.batch_size, 1, shuffle=False)
print(batches)
# Collect the predictions here
print('all_predictions!!')
all_predictions = []
for x_test_batch in batches:
batch_predictions = sess.run(predictions, {input_x: x_test_batch, dropout_keep_prob: 1.0})
batch_scores = sess.run(scores,{input_x: x_test_batch, dropout_keep_prob: 1.0}) #Added
siged_scores = tf.sigmoid(batch_scores) #Added
siged_scores_val = sess.run(siged_scores) #Added
print(siged_scores_val)
#print(batch_scores)
Next to check is what is the impact of using glove in CNN text classification, does it improves any bit ?
After adding glove to CNN text classification the performance improved to some extent, I also trained the model till 4000steps. Before it was trained till 400 steps only. Now the model looked more confident and also it was handling twisted words or new words with ease.
Note: although i see improved prerformance, Still i dont 100% on dataset if i change the questions slightly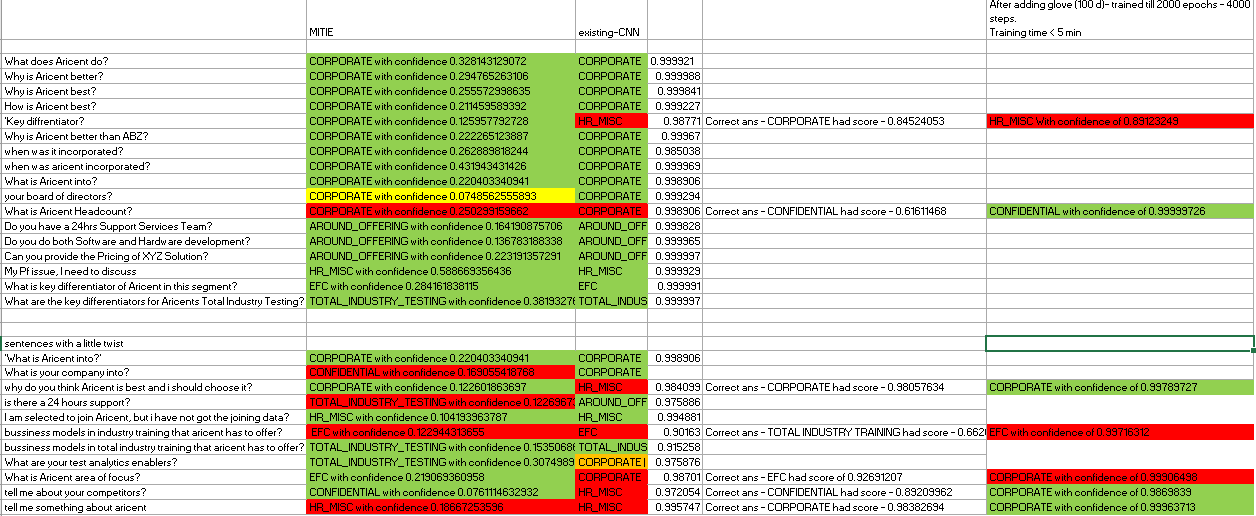
Increasing the training steps didn't help, there was no change in the answers for the questions, however, some of these questions are that donot belong in any category or in 2 category so if model is confused then it is okay.
For adding glove the text_cnn code was changed to below,
import tensorflow as tf
import numpy as np
import sys
import helpers
class TextCNN(object):
"""
A CNN for text classification.
Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer.
"""
def __init__(
self, sequence_length, num_classes, vocab_size,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
# Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
self.vocab_size=vocab_size
self.embedding_size=embedding_size
print("vocab_size=",self.vocab_size)
print("X and Y Shape")
print(self.input_x.shape)
print(self.input_y.shape)
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
#This is random vectors
#self.W = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),name="W")
self.W = self.get_embeddings()
print(self.W)
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
print("Filter shape=",filter_size)
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
print("conv shape=",conv.shape)
conv=tf.Print(conv,[conv],message="Sarwesh conv2d")
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
print("after relu func shape=",h.shape)
h=tf.Print(h,[h],message="Sarwesh after relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
print("after pooled shape=",pooled.shape)
pooled=tf.Print(pooled,[pooled],message="Sarwesh pooled")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
print("h_pool shape=",self.h_pool.shape)
self.h_pool=tf.Print(self.h_pool,[self.h_pool],message="Sarwesh h_pool")
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
print("h_pool_flat shape=",self.h_pool_flat.shape)
self.h_pool_flat=tf.Print(self.h_pool_flat,[self.h_pool_flat],message="Sarwesh h_pool_flat")
# Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
self.h_drop=tf.Print(self.h_drop,[self.h_drop],message="Sarwesh after dropping")
print(self.h_drop.shape)
print("Total number of filters=",num_filters_total)
# Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
l2_loss=tf.Print(l2_loss,[l2_loss],message="Sarwesh l2_loss")
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
print("Score shape=",self.scores.shape)
self.scores=tf.Print(self.scores,[self.scores],message="Scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
self.predictions = tf.Print(self.predictions,[self.predictions],"predictions")
print("Prediction shape=",self.predictions)
# CalculateMean cross-entropy loss
with tf.name_scope("loss"):
self.input_y=tf.Print(self.input_y,[self.input_y],message="Input label")
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
print("Shape of losses=",losses.shape)
losses=tf.Print(losses,[losses],message="losses after softmax")
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1)) # correct_predictions will be like (1,1,1,0,1,1,1...)
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
def get_embeddings(self):
tf.logging.info("Loading Glove embeddings...")
vocab_array, vocab_dict = helpers.load_vocab('custom_vocab.txt')
glove_vectors, glove_dict = helpers.load_glove_vectors('/home/cdpai/tensorflow-models/rateresponses/glove_pretrained_word_embedding/glove.6B.100d.txt', vocab=set(vocab_array))
print(self.embedding_size)
initializer = helpers.build_initial_embedding_matrix(vocab_dict, glove_dict, glove_vectors,self.embedding_size)
return tf.get_variable("word_embeddings",shape=[len(vocab_dict), self.embedding_size],initializer=tf.constant_initializer(initializer))
A helper function from retreival based model was used which is,
import array
import numpy as np
import tensorflow as tf
from collections import defaultdict
import io
def load_vocab(filename):
vocab = None
with open(filename) as f:
vocab = f.read().splitlines()
print(len(vocab))
print(vocab[290:])
dct = defaultdict(int)
for idx, word in enumerate(vocab):
if word in dct.keys():
print("word {} already present",word)
dct[word] = idx
print(len(dct))
return [vocab, dct]
def load_glove_vectors(filename, vocab):
"""
Load glove vectors from a .txt file.
Optionally limit the vocabulary to save memory. `vocab` should be a set.
"""
dct = {}
vectors = array.array('d')
current_idx = 0
with io.open(filename, "r", encoding="utf-8") as f:
for _, line in enumerate(f):
tokens = line.split(" ")
word = tokens[0]
entries = tokens[1:]
if not vocab or word in vocab:
dct[word] = current_idx
vectors.extend(float(x) for x in entries)
current_idx += 1
word_dim = len(entries)
num_vectors = len(dct)
tf.logging.info("Found {} out of {} vectors in Glove".format(num_vectors, len(vocab)))
return [np.array(vectors).reshape(num_vectors, word_dim), dct]
def build_initial_embedding_matrix(vocab_dict, glove_dict, glove_vectors, embedding_dim):
print("Received vocab_dict ",vocab_dict)
print("Received glove_dict ",glove_dict)
print("Received glove_vectors ",glove_vectors)
print("Received embedding_dim ",embedding_dim)
initial_embeddings = np.random.uniform(-0.25, 0.25, (len(vocab_dict), embedding_dim)).astype("float32")
print(initial_embeddings.shape)
for word, glove_word_idx in glove_dict.items():
print("word=",word)
print("glove_word_idx=",glove_word_idx)
word_idx = vocab_dict.get(word)
print("Word_idx=",word_idx)
initial_embeddings[word_idx, :] = glove_vectors[glove_word_idx]
return initial_embeddings
[for retireval based model]
The above model still does not enable us to use unseen words in the questions - or rephrased questions, lets test how it fails or ..pass?
On testing it with some examples, it worked but it also failed for others- still not best to handle rephrased sentences.
I use bidirectional lstm layer using following code,
rnn_outputs, rnn_states = tf.nn.bidirectional_dynamic_rnn(
cell_fw,
cell_bw,
tf.concat([context_embedded, utterance_embedded],0),
sequence_length=sequence_length,#tf.concat([context_len, utterance_len],0),
dtype=tf.float32)
One forward and One backward pass cell, my expectation was performance will improve but it didn't ( note i used 1 cell each and i used output from backward cell ), the performance fell below 3 lstm layer model. Although the performance was better than using 1 lstm layer only.
One doubt : are these LSTM layer connected ? frwd and backwrd layer ..? in keras i can mention that.
Next <TODO> 3 frwd lstm layer 3 backward lstm layer
<TODO>
How about using encoder-decoder model instead of this dual_encoder model? <TODO>
We will proceed with translation model and see if this brings any magic to our solution and problem at hand.
<TOREAD>
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models
and
Attention with Intention for a Neural Network Conversation Model
Bot Framework
rasa - open source NLU - http://rasa.ai/products/rasa-nlu/
rasa gives us to work with three models,
- MITIE
- spacy + sklearn
- sklearn + MITIE
It provides a framework around these models, hence it is easy to train and predict.
We have to have data in json format [ can be seen in the documentation page ]
for intent classification, to prepare json dataset i have created a py file which is present in github.
Upon training the MITIE model with aricent.com data, it is giving i would say above average performance, if i use exact sentences it is identifying intent and with high score, but when i use some different word in the same sentences or may be a spelling mistake then for most intent is correct but score is very low, normally my bot will ask something like "sorry?" for the user to repeat the question but it has already identified the correct intent and if the spelling is not correct, it should not force the user to repeat the question with correct spelling!!. How to handle this?
I want to see if this performance improves if I use spacy + sklearn - spacy has inbuilt word vectors that may be helpful?
Before I start, i recevied errorr - "Exception: Not all required packages are installed. To use this pipeline, you need to install the missing dependencies. Please install sklearn_crfsuite"
Installed sklearn_crfsuite.
After this the training was very fast, it completed in 0.2 seconds - this is doubtful!!
When i try to run predict.py function it fails with error
TypeError: Argument 'string' has incorrect type (expected unicode, got str)
Solution found - https://github.com/explosion/spaCy/issues/212
But import future package didnt work, so i added question.decode('utf-8'), this worked.
Now time to test the model!!
The model comparatively performed less than MITIE, it failed for some question which MITIE model found out correct!! ..why? dont know. For some question, both model failed to ans correct.
Sentence Embedding - https://medium.com/towards-data-science/sentence-embedding-3053db22ea77
What is sentence Embedding?
You know word embedding - how to determine closeness of words in a low dimension space, benefit is that it not only improves the model efficiency but also improves in the time it takes to train the models. Similarly, we have sentence embedding, this comes into picture when we are dealing with dialog or conversation scenario where we have to maintain context - if the conversation sentence is closer to the one already asked before then the context is maintained, although intent can be different.
Starting with Tensorflow Model-Zoo - https://github.com/tensorflow/models
start with textsum and adversarial neural cryptography.